目次
概要(目的・背景)
現代のビジネス環境では、顧客が特定の商品を購入するか否か、メールがスパムであるかどうかなど、二者択一の予測が求められる場面が多々あります。これらの予測を高精度で行うための手法として、ロジスティック回帰分析を紹介します。特に、データの可視化に優れたPower BIと、柔軟なデータ操作が可能なPythonを組み合わせることで、より深い洞察を得ることが可能です。
読み手(誰に向けた記事か?)
本記事は、データ分析に関心をお持ちの中級者を対象としています。特に、日々の業務でデータ分析を行い、新しい手法の導入を検討されているデータアナリストの方にとって、有益な内容となっています。また、データサイエンス分野に興味を持ち、統計的手法を学びたいとお考えのPythonプログラマーの方にとっても、実践的な知識を習得する機会を提供します。
ブログの目標設定(具体的な目標)
本記事の具体的な目標は以下の通りです。
・ロジスティック回帰分析の基本概念を理解する
この手法がどのような問題に適用され、どのように機能するのかを解説します。
・Power BIとPythonを連携させた分析手法を習得する
データの可視化と高度な分析を組み合わせる方法を具体的に紹介します。
これらの目標を達成することで、読者の皆さんがデータ分析の幅を広げ、より高度な予測モデルを構築できるようになることを目指します。
方法(アプローチ・使用技術)
ロジスティック回帰分析とは?
まず、ロジスティック回帰分析について簡単に説明します。ロジスティック回帰は、ある事象が発生する確率を予測するための統計的手法です。例えば、顧客が商品を購入するか否か、メールがスパムであるかどうかといった二値の結果を予測する際に用いられます。この手法は、入力変数と出力変数の関係性をモデル化し、出力が「0/1」、「Yes/No」のどちらかになるような予測を行います。
例えば、以下のような「Yes/No」「0/1」の二値を予測する場面で利用されます。
・マーケティング分野: 顧客が商品を購入するかしないか(1: 購入する, 0: 購入しない)
・医療分野: ある患者が病気にかかるかどうか(1: かかる, 0: かからない)
・金融分野: 顧客がローンを延滞するかどうか(1: 延滞する, 0: 延滞しない)
・メールフィルタリング: 受信メールがスパムかどうか(1: スパム, 0: スパムでない)
・人事分野:従業員が退職するかどうか(1: 退職する可能性がある, 0: 退職する可能性がない)
線形回帰との違い
ロジスティック回帰は、「回帰」という名前がついていますが、実際には分類問題に使われます。
線形回帰とロジスティック回帰の違いは次の通りです。
| 線形回帰 | ロジスティック回帰 | |
|---|---|---|
| 目的 | 連続値の予測 (例: 売上、気温) | 二値分類 (例: 購入するかしないか) |
| 出力 | 実数値(-∞ から ∞) | 0〜1の確率 |
ロジスティック回帰のモデル学習
(参考程度です。Pythonのライブラリが自動で計算してくれます。)
ロジスティック回帰の学習では、データに最も適したパラメータである重みとバイアスを求めることが目的となります。そのために、モデルの出力確率と実際のラベルとの差を評価する損失関数を最小化する必要があります。
ロジスティック回帰では、尤度関数を最大化する形で学習を行います。データが正しいラベルを持つ確率の積を尤度関数とし、計算を容易にするために対数尤度関数を用います。対数尤度関数では、予測確率の対数を取ったものを合計し、モデルが正しい予測をするほど値が小さくなるように設計されています。これを最小化することで、最適なパラメータを求めます。
この最適化には、勾配降下法という手法が広く用いられます。勾配降下法では、損失関数の勾配を計算しながら、少しずつ重みを調整して最適な値に近づけます。この際に、学習率というパラメータが重要となり、学習率が大きすぎると適切な値に収束しにくく、逆に小さすぎると学習に時間がかかるため、適切な値を設定することが求められます。
この学習プロセスを繰り返すことで、モデルはデータに適した分類境界を学習し、新しいデータに対しても確率を計算しながら適切に分類できるようになります。
ロジスティック回帰のメリット・デメリット
メリット
・ 計算コストが低い
→ 計算量が少ないため、実装や運用の負荷が低い。
・ 確率として出力される
→ 例えば、「このメールがスパムである確率は 85%」といった解釈が可能。
・特徴量の重要度を評価しやすい
→係数の大きさや符号を分析することで、どの特徴量が目的変数に影響を与えているかを把握しやすい
デメリット
・非線形なデータには適さない
→ 説明変数と目的変数の関係が複雑な場合、精度が下がる。
・ 外れ値に弱い
→ 極端なデータ(外れ値)があると、モデルの精度が低下することがある。
ロジスティック回帰分析の設定手順
【前提】
Power BIのPowerQueryを用いてロジスティック回帰分析を作成します。ロジスティック回帰分析の設定を完了したPower BIファイルは下記の添付ファイルです。必要な設定はすべて完了していますので、添付ファイルをベースにロジスティック回帰分析の設定方法を説明していきます。

今回用意しているデータは、エンゲージメントサーベイと労働時間(エンゲージメント調査データ)の結果を用いて、ロジスティック回帰分析のモデルを作成します。モデル作成後、予測データをCSVファイルで取り込み、離職の有無を予測します。
そのため、用意したデータは2種類あります。
・モデル作成用のCSVデータ(LogisticRegression.csv)
・予測用のCSVデータ(forevast.csv)
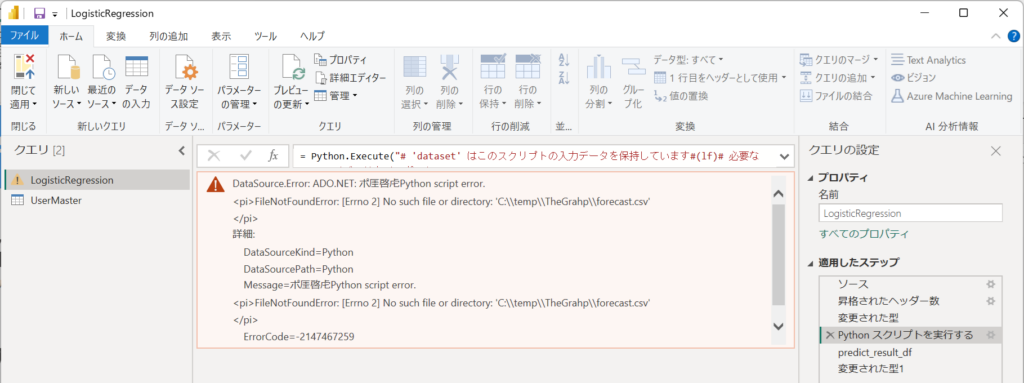
PowerQueryエディターにて、設定を確認するとき、以下のパスに予測用のCSVファイルを配置してください。
配置先:'C:\temp\TheGrahp\forecast.csv'
配置しない場合、以下のメッセージが表示されますのでご注意ください。
1.「LogisticRegression.pbix」をダブルクリックして開く。
2.「ホーム」タブから「データの変換」ボタンを押下する。
3.左メニューのLogisticRegressionを選択する。
※LogisticRegressionへロジスティック回帰分析の設定を入れています。
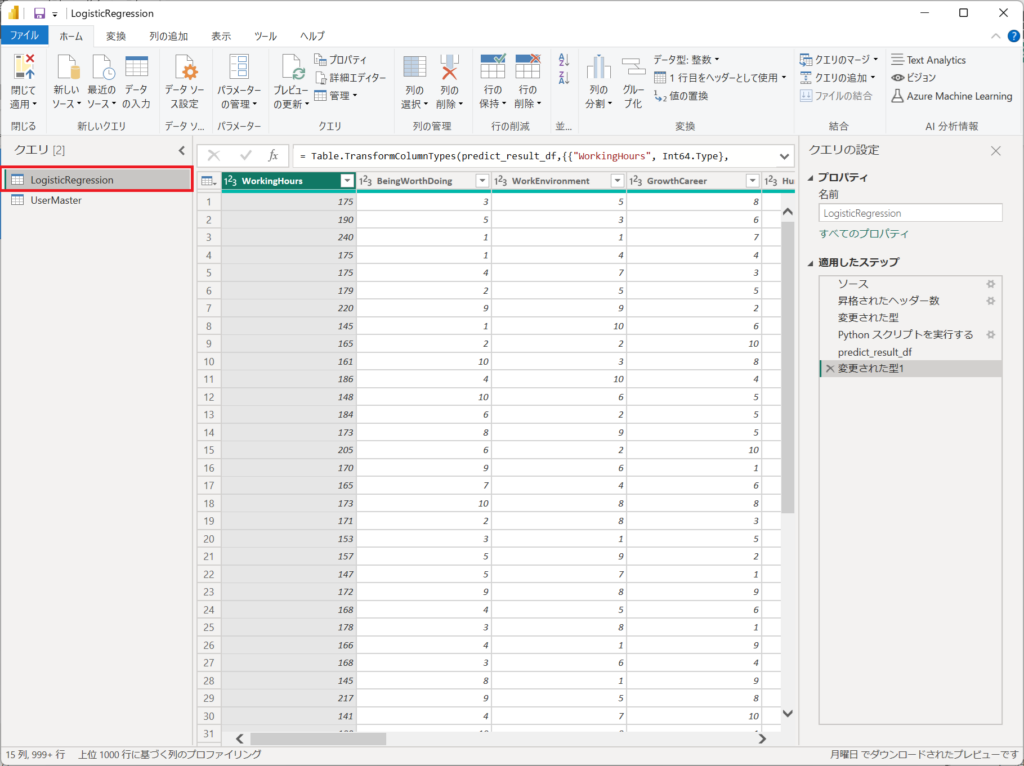

PowerQueryは3つで構成されています。
各ステップを説明していきます。
①.エンゲージメント調査データのCSV取得
②.取り込んだデータに対してPythonにてロジスティック回帰分析を実施
③.ロジスティック回帰分析の結果をテーブルへ展開
4.「ソース、昇格されたヘッダー数、変更された型」は①エンゲージメント調査データのCSV取得の処理です。Power BIへCSVを取り込むときに自動で設定される定義です。
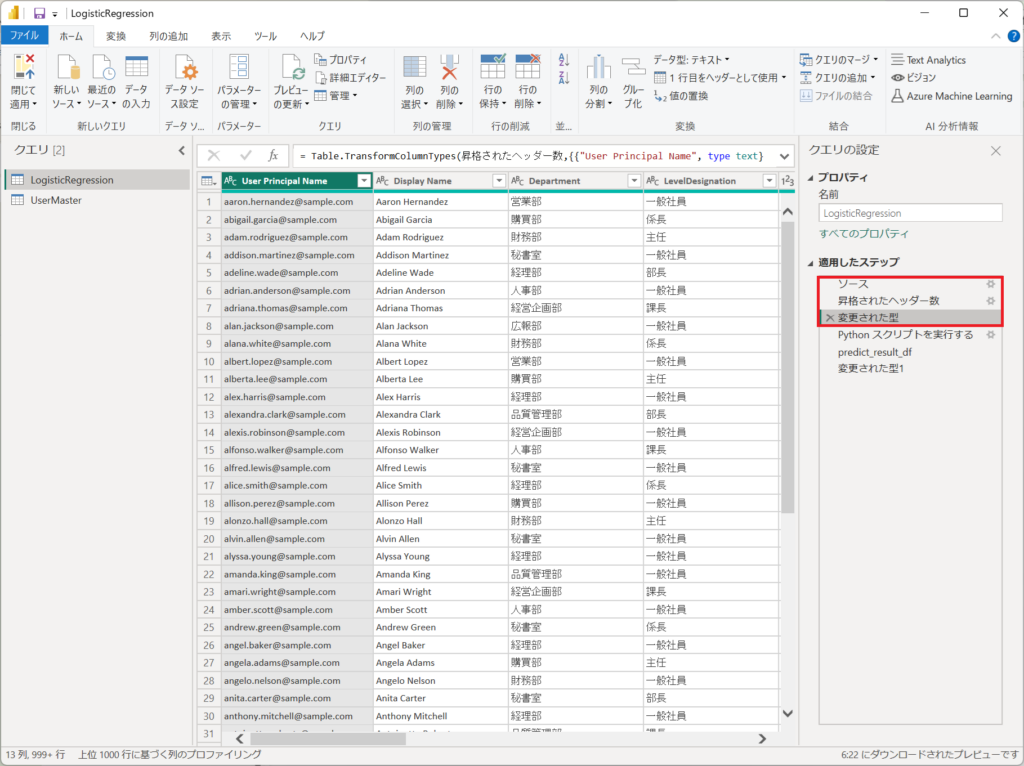
"データ分析の第1歩 ~データ取り込みの基礎知識➊~(Day1)"で行っているCSV取り込み処理と同じ手順であるため、詳細な説明は下記のリンク先を参照してください。

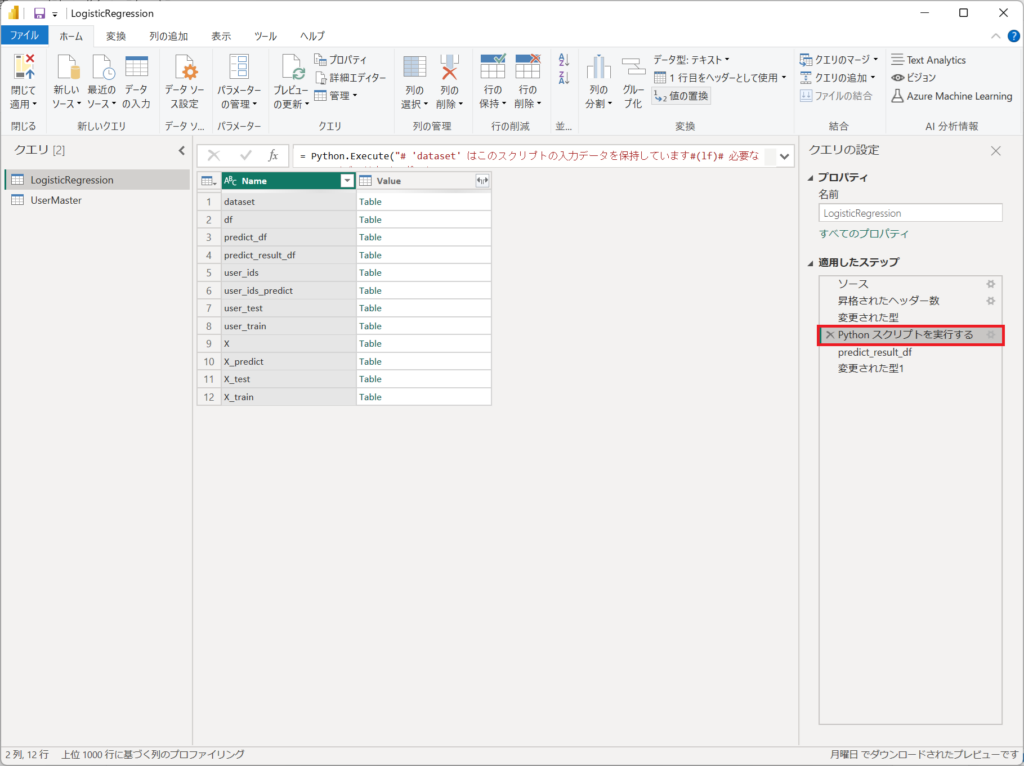
5.「Pythonスクリプトを実行する」は、本記事のメインとなる「ロジスティック回帰分析」のコードが定義されたステップです。
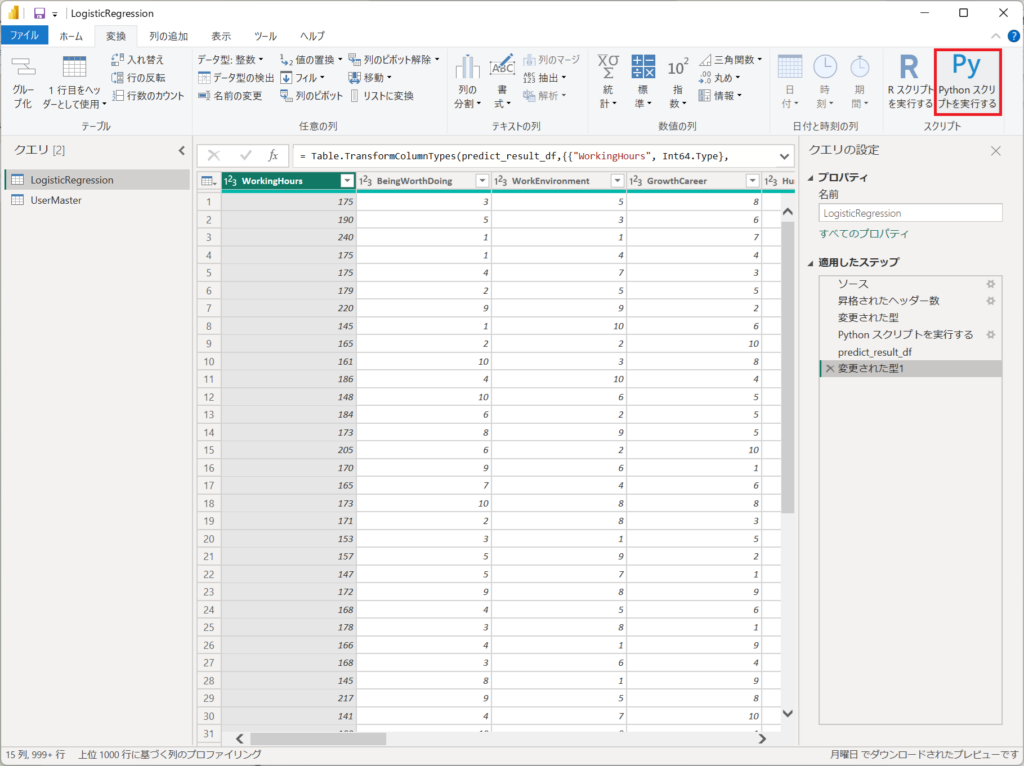
6.Power QueryでPythonを実行する手順を詳細に説明します。
①.Pythonのステップを入れるときは「変換」タブから「Pythonスクリプトを実行する」ボタンを押下する。
②.Pythonコードを入力する、ウィンドウが立ち上がります。
画面中央のスクリプトへPythonのコードを入力します。
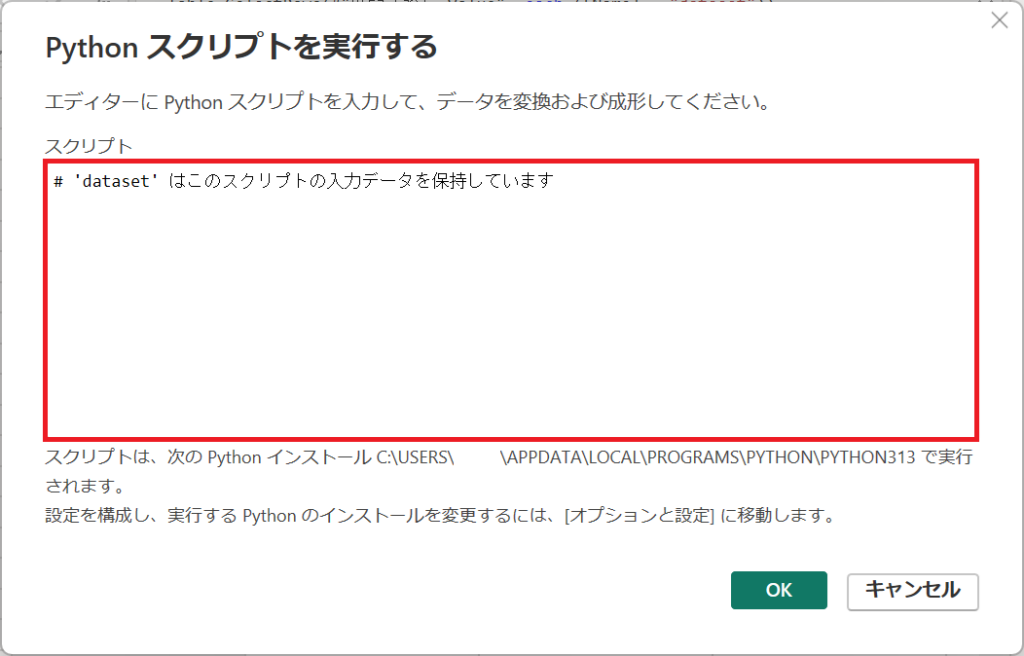
③.以下のコードを入力する。
# 'dataset' はこのスクリプトの入力データを保持しています
# 必要なライブラリをインポート
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report, roc_curve, roc_auc_score
# Power BI からデータフレームを取得
df = dataset
# 'User Principal Name' を別に保持
user_ids = df[['User Principal Name']]
# 説明変数の設定(独立変数)
X = df[['WorkingHours', 'BeingWorthDoing', 'WorkEnvironment',
'GrowthCareer', 'HumanRelations', 'EvaluationApproval']]
# 目的変数の設定(従属変数)
y = df['JobRotationReserve']
# 訓練データとテストデータに分割(80%:20%)
X_train, X_test, y_train, y_test, user_train, user_test = train_test_split(
X, y, user_ids, test_size=0.2, random_state=42
)
# 標準化(スケール調整)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# ロジスティック回帰モデルの作成と学習
model = LogisticRegression(class_weight='balanced')
model.fit(X_train_scaled, y_train)
# クラス1(JobRotationReserve=1)の確率を予測
y_prob = model.predict_proba(X_test_scaled)[:, 1]
# ROC曲線から最適なしきい値を見つける
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
optimal_idx = (tpr - fpr).argmax()
optimal_threshold = thresholds[optimal_idx]
# AUCスコアを計算
auc_score = roc_auc_score(y_test, y_prob)
# 最適なしきい値を適用して予測
y_pred_adjusted = (y_prob > optimal_threshold).astype(int)
# 予測と精度評価
accuracy = accuracy_score(y_test, y_pred_adjusted)
report = classification_report(y_test, y_pred_adjusted, output_dict=True)
# 変数の寄与度を算出
coefs = model.coef_[0]
stds = np.std(X_train_scaled, axis=0)
feature_importance = (coefs * stds) ** 2
feature_importance /= feature_importance.sum() # 割合に変換
# 結果をデータフレーム化
importance_df = pd.DataFrame({
'Feature': X.columns,
'Coefficient': coefs,
'Importance': feature_importance
}).sort_values(by='Importance', ascending=False)
# ====== ここから CSV 予測用の処理 ======
# CSVファイルを読み込む
csv_path = r'C:\temp\TheGrahp\forecast.csv' # ファイルパス
predict_df = pd.read_csv(csv_path)
# CSVファイルに 'User Principal Name' が含まれている場合、それを保持
user_ids_predict = predict_df[['User Principal Name']]
# 学習データと同じ特徴量を抽出
X_predict = predict_df[['WorkingHours', 'BeingWorthDoing', 'WorkEnvironment',
'GrowthCareer', 'HumanRelations', 'EvaluationApproval']]
# 標準化を適用
X_predict_scaled = scaler.transform(X_predict)
# モデルを使って確率を予測
y_prob_predict = model.predict_proba(X_predict_scaled)[:, 1]
# 最適なしきい値を適用して予測クラスを決定
y_pred_adjusted_predict = (y_prob_predict > optimal_threshold).astype(int)
# 結果をデータフレームにまとめる
predict_result_df = X_predict.copy()
predict_result_df['User Principal Name'] = user_ids_predict['User Principal Name'].values
predict_result_df['予測値'] = y_pred_adjusted_predict
predict_result_df['クラス1確率'] = y_prob_predict
predict_result_df['最適なしきい値'] = optimal_threshold
predict_result_df['AUCスコア'] = auc_score # AUCスコアを追加
predict_result_df['モデル精度'] = accuracy
predict_result_df['適合率_1'] = report['1']['precision']
predict_result_df['再現率_1'] = report['1']['recall']
predict_result_df['F1スコア_1'] = report['1']['f1-score']
# 予測結果の出力
predict_result_dfコードを順に説明します。
1. 必要なライブラリのインポート
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report, roc_curve, roc_auc_score・numpy:数値計算ライブラリ
・pandas: データフレームの操作用
・train_test_split: データを訓練用・テスト用に分割
・LogisticRegression: ロジスティック回帰モデルを作成
・StandardScaler:データの標準化(スケール調整)
・accuracy_score, classification_report: モデルの評価指標を算出
・roc_curve, roc_auc_score: ROC 曲線および AUC(Area Under the Curve)スコアを算出
2. データの取得
df = dataset
user_ids = df[['User Principal Name']]
Power BI からデータを取得し、df に格納します。
User Principal Name(ユーザー識別子)を別に保持しておきます。3. 説明変数(X)と目的変数(y)の設定
X = df[['WorkingHours', 'BeingWorthDoing', 'WorkEnvironment',
'GrowthCareer', 'HumanRelations', 'EvaluationApproval']]
y = df['JobRotationReserve']・説明変数(X): 6つの職場環境に関連する変数(勤務時間、仕事のやりがい、職場環境、キャリア成長、人間関係、評価と承認)
・目的変数(y): JobRotationReserve(離職予備軍のフラグ(1:離職予備軍)
4. 訓練データとテストデータの分割
X_train, X_test, y_train, y_test, user_train, user_test = train_test_split(
X, y, user_ids, test_size=0.2, random_state=42
)・データを 80%:20% に分割し、random_state=42 により再現性を確保
・user_ids も分割し、後でテストデータに対するユーザー識別情報を活用
5.データの標準化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)・StandardScaler を用いて、学習データ (X_train) の各特徴量を標準化(平均0・標準偏差1)します。
・テストデータ (X_test) にも同じスケーリングを適用します。
5. ロジスティック回帰モデルの作成と学習
model = LogisticRegression(class_weight='balanced')
model.fit(X_train_scaled, y_train)・class_weight='balanced' により、不均衡データへの対応を考慮
・訓練データ (X_train_scaled, y_train) を用いてモデルを学習
6. 予測と最適なしきい値の算出
y_prob = model.predict_proba(X_test_scaled)[:, 1]・predict_proba を使用して、クラス 1 (JobRotationReserve=1) の確率を取得
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
optimal_idx = (tpr - fpr).argmax()
optimal_threshold = thresholds[optimal_idx]・ROC曲線 を用いて最適なしきい値を算出
・tpr - fpr が最大となる点を最適なしきい値として選択
auc_score = roc_auc_score(y_test, y_prob)・AUCスコア を計算し、モデルの性能を評価
7. しきい値を適用した予測と評価
y_pred_adjusted = (y_prob > optimal_threshold).astype(int)・最適なしきい値を適用し、予測クラス(0または1)を決定
accuracy = accuracy_score(y_test, y_pred_adjusted)
report = classification_report(y_test, y_pred_adjusted, output_dict=True)・精度(accuracy) と 分類レポート(適合率、再現率、F1スコア) を算出
7.変数の寄与度の算出
coefs = model.coef_[0]
stds = np.std(X_train_scaled, axis=0)
feature_importance = (coefs * stds) ** 2
feature_importance /= feature_importance.sum()
importance_df = pd.DataFrame({
'Feature': X.columns,
'Coefficient': coefs,
'Importance': feature_importance
}).sort_values(by='Importance', ascending=False)・ロジスティック回帰モデルの係数を標準偏差と掛け合わせることで、各特徴量の寄与度を計算しています。
・feature_importance を合計1になるように正規化し、影響度の割合を出力します。
ここまでがモデルの作成とモデルの評価です。
以降は、予測用のCSVファイル(forecast.csv)に対して、作成したモデルで「予測」を行います。
8. CSV ファイルを用いた新規データの予測
csv_path = r'C:\temp\TheGrahp\forecast.csv'
predict_df = pd.read_csv(csv_path)・予測用の CSV データを読み込む
user_ids_predict = predict_df[['User Principal Name']]
X_predict = predict_df[['WorkingHours', 'BeingWorthDoing', 'WorkEnvironment',
'GrowthCareer', 'HumanRelations', 'EvaluationApproval']]・User Principal Name を保持し、学習データと同じ説明変数を抽出
X_predict_scaled = scaler.transform(X_predict)
y_prob_predict = model.predict_proba(X_predict)[:, 1]
y_pred_adjusted_predict = (y_prob_predict > optimal_threshold).astype(int)・モデルを用いて 確率を予測
・最適なしきい値を適用 し、予測クラスを決定
9. 予測結果の整理
predict_result_df = X_predict.copy()
predict_result_df['User Principal Name'] = user_ids_predict['User Principal Name'].values
predict_result_df['予測値'] = y_pred_adjusted_predict
predict_result_df['クラス1確率'] = y_prob_predict
predict_result_df['最適なしきい値'] = optimal_threshold
predict_result_df['AUCスコア'] = auc_score
predict_result_df['モデル精度'] = accuracy
predict_result_df['適合率_1'] = report['1']['precision']
predict_result_df['再現率_1'] = report['1']['recall']
predict_result_df['F1スコア_1'] = report['1']['f1-score']
predict_result_df・予測値、確率、しきい値、AUCスコア、モデル評価指標 をデータフレームにまとめる
6.「Pythonスクリプトで実行する」の結果から、「predict_result_df」を展開すると、ステップに「predict_result_df」と「変更された型1」が自動生成されます。
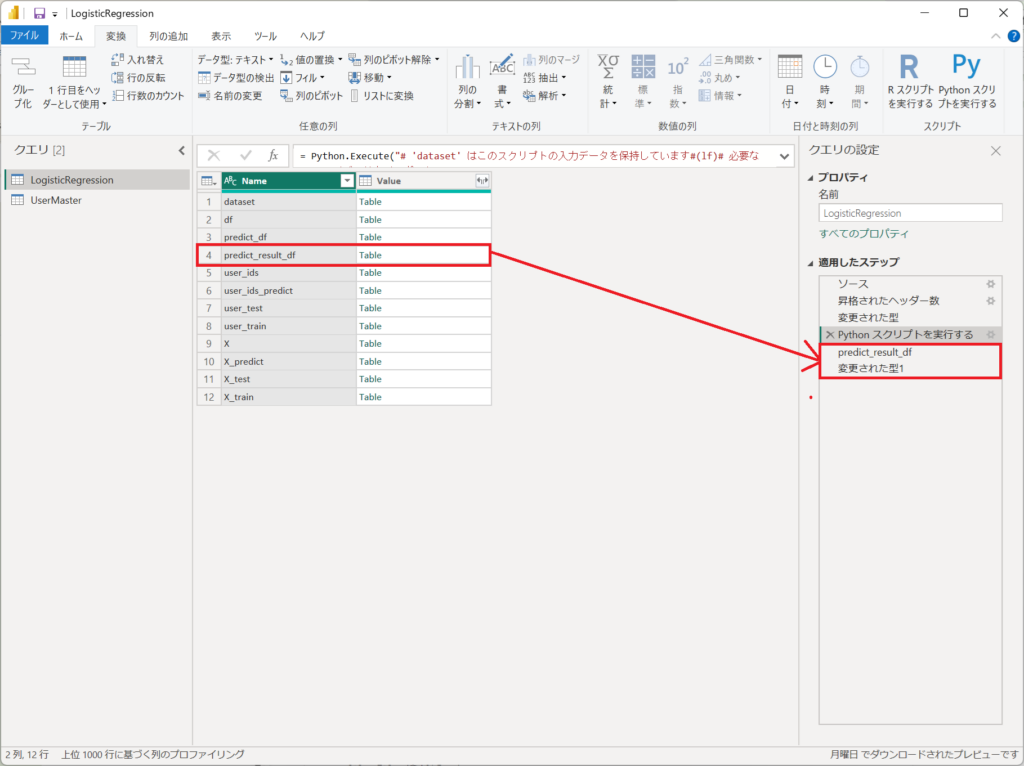
7.カードのビジュアルを配置して、①~④を以下の列を設定にする。
①・・・"LogisticRegression"テーブル、モデル精度 列
②・・・"LogisticRegression"テーブル、再現性_1 列
③・・・"LogisticRegression"テーブル、適合率_1 列
④・・・"LogisticRegression"テーブル、AUCスコア 列 (*平均)
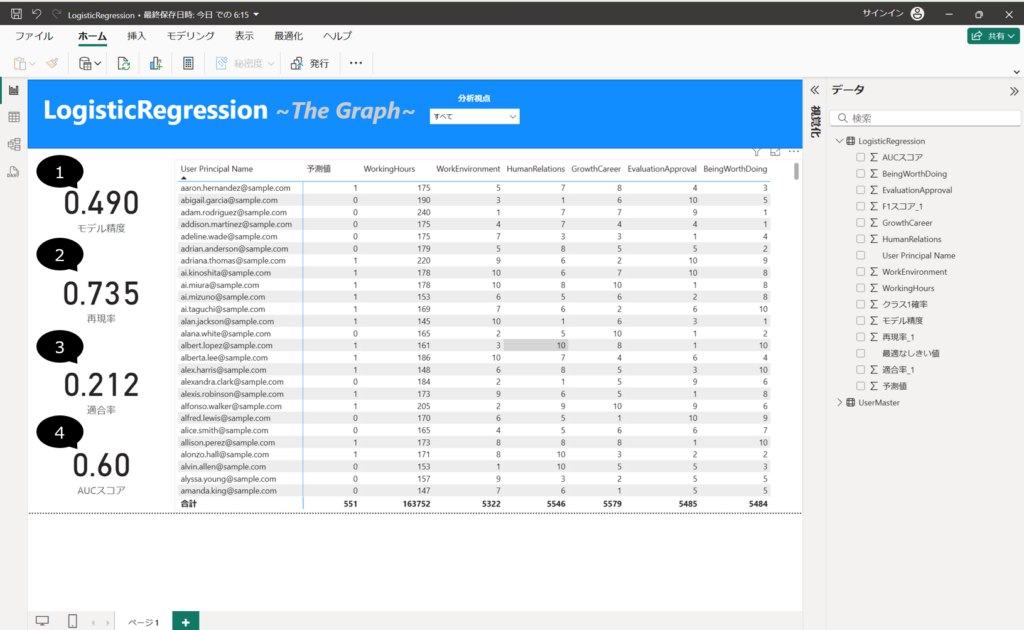
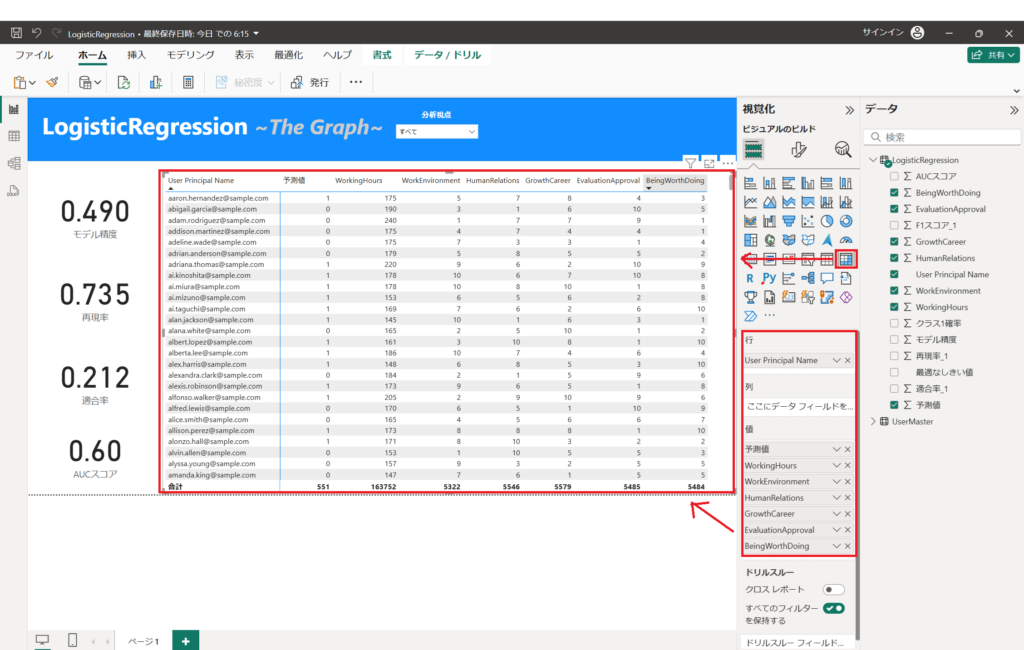
8.マトリックスのビジュアルを配置して、以下の列を設定する。
行・・・"LogisticRegression"テーブル、User Principal Name 列
列・・・"LogisticRegression"テーブル、予測値 列、WorkingHours列、 WorkEnvironment列、HumanRelations列、GrowthCareer列、EvaluationApproval列、BeingWorthDoing列
ロジスティック回帰分析にて、離職を予測しました。
引き続き、グラフの読み方を解説します。

まとめ(結論と今後の展望)
本記事では、ロジスティック回帰分析の基本概念から始め、Power BIとPythonを連携させた具体的な分析手法について解説しました。データの可視化と高度な分析を組み合わせることで、ビジネスにおける意思決定をより効果的に行うことが可能となります。
Power BIとPythonの連携を活用し、より効果的なデータ活用を目指してみてください。