目次
概要(目的・背景)
近年、AI技術の進化により、私たちの生活やビジネスの現場で機械学習が広く活用されています。例えば、スマートフォンの音声アシスタントが私たちの話す言葉を理解し、適切な応答を返すのも、機械学習の力によるものです。また、NetflixやYouTubeが個々のユーザに最適なコンテンツを推薦する背後にも、機械学習が重要な役割を果たしています。このように、機械学習は私たちの日常生活に深く浸透していますが、その仕組みや種類については、まだ理解が浅い方も多いのではないでしょうか。本記事では、機械学習の基本的な概念や種類、具体的な手法、そして身近な活用事例について、わかりやすく解説していきます。
読み手(誰に向けた記事か?)
本記事は、機械学習に関心を持ち始めた初学者の方々を主な対象としています。具体的には、AIやデータサイエンスに興味を持ち、これから学び始めたいと考えている学生や社会人の方、またビジネスの現場でデータ分析を活用したいと考えているマーケティング担当者や経営者の方を想定しています。さらに、すでにプログラミングの経験があるものの、機械学習の具体的な手法や応用例について知識を深めたいと考えているエンジニアの方にとっても、本記事が有益な内容となるよう構成しています。
専門的な知識がなくても理解できるよう、できるだけ平易な言葉を用いるとともに、具体的な事例を交えながら解説を進めていきます。そのため、機械学習に関する予備知識がない方でも、安心して読み進めていただければと思います。
ブログの目標設定(具体的な目標)
本記事の目標は、読者の皆さんが機械学習の基本的な概念や種類、具体的な手法、そして身近な活用事例について理解を深めることです。具体的には、以下の成果を目指します。
・機械学習の基本的な概念や種類を説明できるようになる。
・代表的な機械学習の手法について、その概要と用途を理解する。
・Power BIで機械学習を実装するための概要を理解する。
方法(アプローチ・使用技術)
機械学習の基本概念
機械学習は、従来のルールベースのプログラムとは異なり、データを活用してモデルを学習し、自動的にパターンを発見する点が特徴です。主な機械学習の手法には以下の3つがあります。
| No | 機械学習 | 概略 |
|---|---|---|
| ① | 教師あり学習 (Supervised Learning) | 既知のデータを元に予測を行う。 |
| ② | 教師なし学習 (Unsupervised Learning) | 未知のデータ構造を分析し、パターンを発見する。 |
| ③ | 強化学習 (Reinforcement Learning) | 試行錯誤を通じて最適な行動を学ぶ。 |
各機械学習について説明します。
①.教師あり学習
教師あり学習は、入力データ(特徴量)と、それに対応する正解ラベル(ターゲット)のペアを用いて学習を行う手法です。目的変数(ターゲット)の種類によって、分類(Classification) と 回帰(Regression) に大別されています。主に分類はスパムメール判定や画像認識(猫 or 犬)、回帰は売上予測、気温予測に用いられています。
| 種別 | 手法/モデル | 説明 |
|---|---|---|
| 分類(Classification) | ロジスティック回帰 (Logistic Regression) | 確率的な分類モデルであり、二値分類や多クラス分類に適用可能。 |
| サポートベクターマシン (Support Vector Machine, SVM) | クラス間のマージンを最大化する境界を求める手法。 | |
| 決定木(Decision Tree) | データを条件分岐により分類し、過学習を抑えるために複数の決定木を組み合わせるアンサンブル手法。 | |
| 回帰 (Regression) | 線形回帰 (Linear Regression) | 最も基本的な回帰モデルで、変数間の線形関係を学習する。 |
| 勾配ブースティング(Gradient Boosting) | XGBoostやLightGBMなどの手法があり、決定木を連鎖的に学習させることで高精度な回帰が可能。 |
②.教師なし学習
教師なし学習は、ラベルのないデータから構造やパターンを発見する手法であり、主に クラスタリング(Clustering) と 次元削減(Dimensionality Reduction) に分類されています。顧客セグメンテーションや画像データの特徴抽出に活用されています。
| 種別 | 手法/モデル | 説明 |
|---|---|---|
| クラスタリング (Clustering) | K-means | データをK個のクラスタに分割し、クラスタの中心(セントロイド)を iteratively 更新。 |
| 階層的クラスタリング (Hierarchical Clustering) | データの階層構造をツリー状に分割。 | |
| 次元削減 (Dimensionality Reduction) | 主成分分析 (PCA, Principal Component Analysis) | 分散を最大化する軸を見つけることで次元を削減する。 |
| t-SNE (t-Distributed Stochastic Neighbor Embedding) | 非線形次元削減手法で、データの分布を可視化するのに適している。 |
③.強化学習
強化学習は、エージェントが環境との相互作用を通じて、試行錯誤しながら最適な行動を学習する手法です。エージェントは 状態(State) を観測し、行動(Action) を選択し、環境から報酬(Reward)を受け取る。この試行錯誤のプロセスを通じて、最大の累積報酬を得る方策(Policy)を学習します。
| 種別 | 手法/モデル | 説明 |
|---|---|---|
| モデルベース (Model-based RL) | Dyna-Q、Model Predictive Control、モンテカルロ木探索 | 環境の遷移モデルを推定し、計画的に最適な行動を選択。 |
| モデルフリー (Model-free RL) | Q学習(Q-Learning)、モンテカルロ法(Monte Carlo Methods)、Sarsa など | 環境のモデルを推定せず、経験から直接方策を学習。 |
機械学習の手法は、データの性質や目的に応じて適切に選択することが重要です。実務で利用する際には、特徴量が多数ある場合やデータの種類が多様な場合、次元削減やクラスタリングを行ったり、業務データを用いた予測を行ったりすることが多いです。ご自身の目的に応じて、適切な手法を選択していただければと思います。
Power BIで機械学習を組み込むためには
Power BI Desktopには機械学習が実装されてません。Power BIで機械学習を組み込むためにはどうすればよいでしょうか?その答えは、Python or R言語を利用します。本ブログサイトはPyhtonを用いて解説を行います。
Power BI DesktopはPythonと連携することができます。Pythonを利用することで、Power BI内で高度なデータ処理を行い、機械学習を可能とします。pandasなどの強力なライブラリを使用することで、データクレンジングや変換をスムーズに行えるため、分析業務の自動化にも役立ちます。主にPythonが実装できるスキームは、①.データ取り込み時のPowerQueryもしくは、②.ビジュアル設定(Pythonビジュアル)にて行えます。
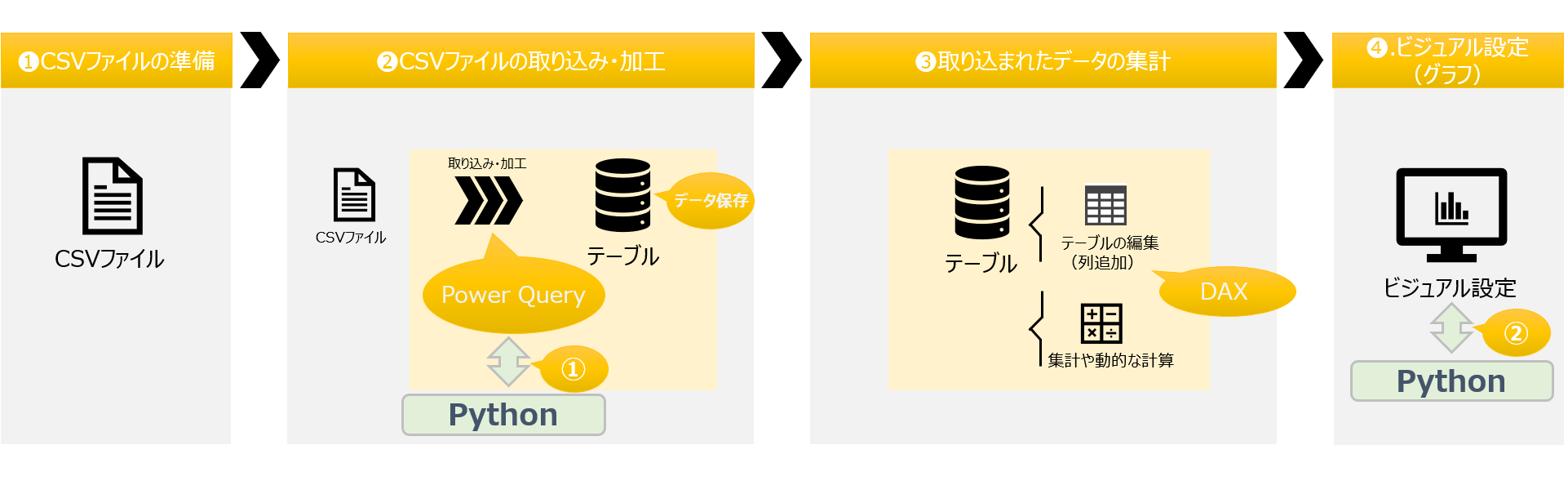
各々のメリットデメリットを整理します。
①.Power QueryでPythonを利用する場合
Power Query を使うことで、データのインポートや変換を効率的に行うことができます。Python を活用すれば、標準の変換機能では対応しきれない複雑なデータ処理や機械学習モデルの適用が可能になります。
メリット
・データの前処理やクレンジングを Python で高度に実施できる
・一度作成したスクリプトを再利用しやすく、定期的なデータ更新にも対応可能
・Python で処理したデータを Power BI 標準ビジュアルやスライサーと組み合わせて使えるため、インタラクティブ性を維持できる
デメリット
・データの前処理、クレンジングの処理に限られるため、Pythonのmatplotlib や seaborn を使った高度な可視化は不可
②.ビジュアル設定にてPythonを利用する場合
Power BI のビジュアルに Python を実装することで、データの可視化がさらに充実します。Python ビジュアルを利用すれば、グラフやチャートを独自に作成し、複雑な分析結果を直感的に表示できます。
メリット
・matplotlib や seaborn を使った高度な可視化が可能
・機械学習モデルの予測値をグラフ上にプロットできる
・ダッシュボードに動的な分析結果を埋め込める
デメリット
・インタラクティブな操作が標準ビジュアルよりも制限されている

本ブログでは、Pythonで機械学習を行いながら、メリット・デメリットを実際に体感していただければと思います。
まとめ(結論と今後の展望)
さまざまな機械学習の手法について説明しましたが、「機械学習」と一言でいっても、その目的に応じて選択肢は多岐にわたります。まずは目的を明確に定め、何をしたいか(Will)をしっかりと把握したうえで、取り組んでいただければと思います。
また、Power BI で Python を活用することで、データ分析の幅が大きく広がります。Power Query を用いたデータ処理や、ビジュアルを活用した高度な可視化など、利用シーンに応じて使い分けていきましょう。特に、Power BI 上で分析と可視化を一体化できることが大きな強みです!