はじめに
「機械学習-モデル保存のススメ」の続きとなりますので、事前に「機械学習-モデル保存のススメ」をご一読いただけますと幸いです。

機械学習モデルを再利用するとは
機械学習モデルを再利用するとは、過去に構築・学習させたモデルを新たなデータに適用し、予測や判断を行うことを意味します。これは、一度作成したルールや戦略を、時間や環境を超えて「資産」として活用することにほかなりません。
たとえば、人材の離職予測モデルをPythonで構築し、精度の高い結果を得られたとします。このモデルを保存しておけば、今後Power BIから入力された新しい社員アンケートデータに対しても、即座に離職リスクをスコア化できるようになります。このように、再学習や再構築を行わなくても、すぐにアウトプットを得られる点が、再利用の大きなメリットです。再利用の際に重要なのは、「同じスケーリング処理を行う」「入力の特徴量が一致している」といった前提条件を満たしていることです。
今回の例では、あらかじめscaler.pklとlogistic_model.pklとして保存しておいたスケーラーとモデルを読み込み、新しいデータにそのまま適用することで、Power BI側から予測処理が可能になっています。
方法(アプローチ・使用技術)
以下のPower BIファイルを使って、モデルの再利用を行います。

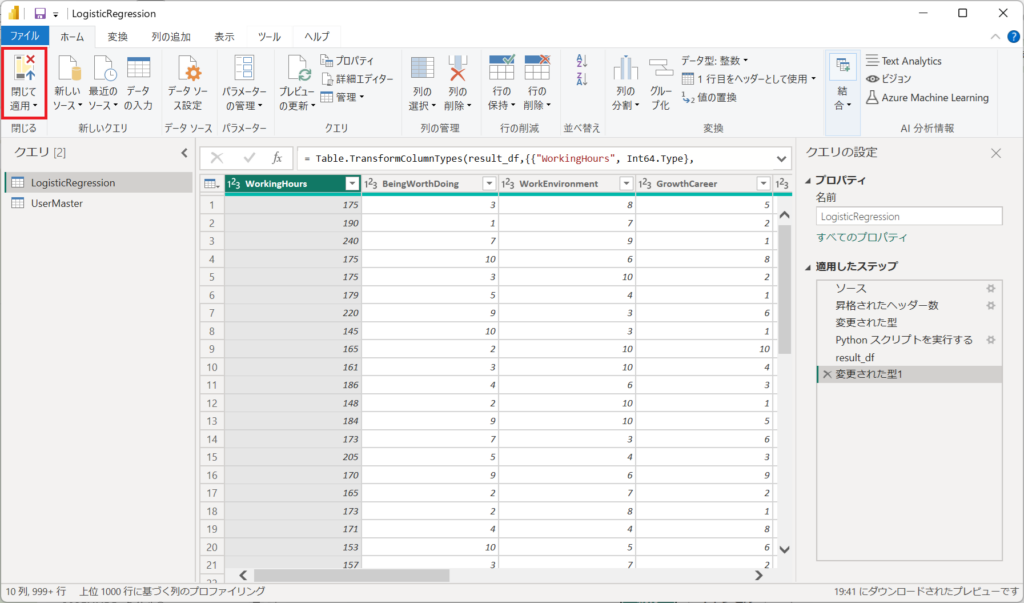
1.リンク先のpbixファイルを開いて、「ホーム」タブより「データの変換」ボタンを押下する。
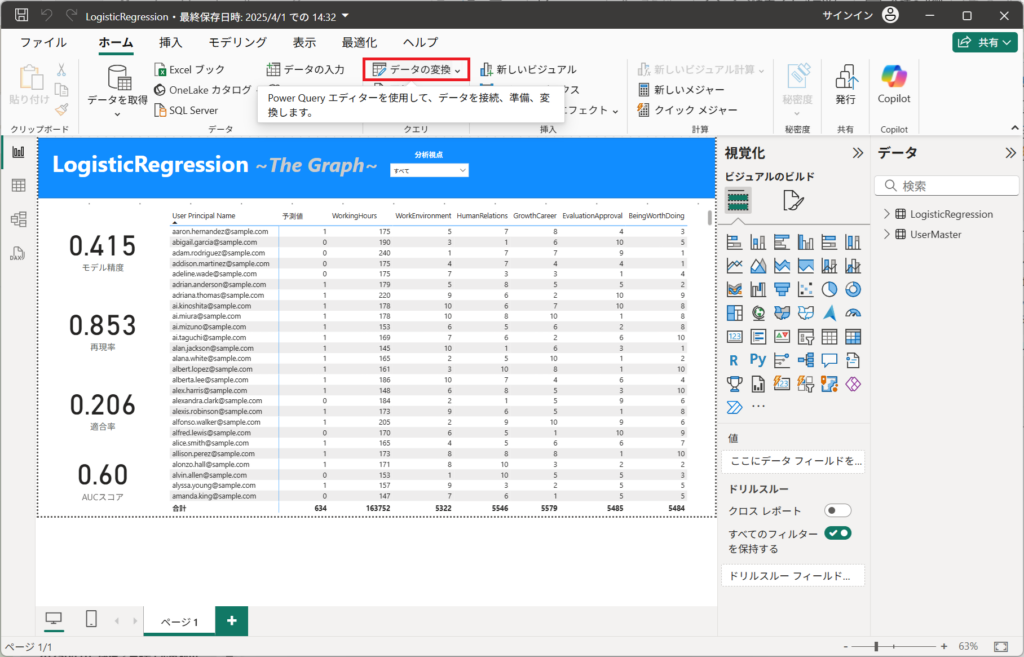
2.左メニューより「LogisticRegression」を選択して、適用したステップから「Pythonスクリプトを実行する」のねじマークを選択する。
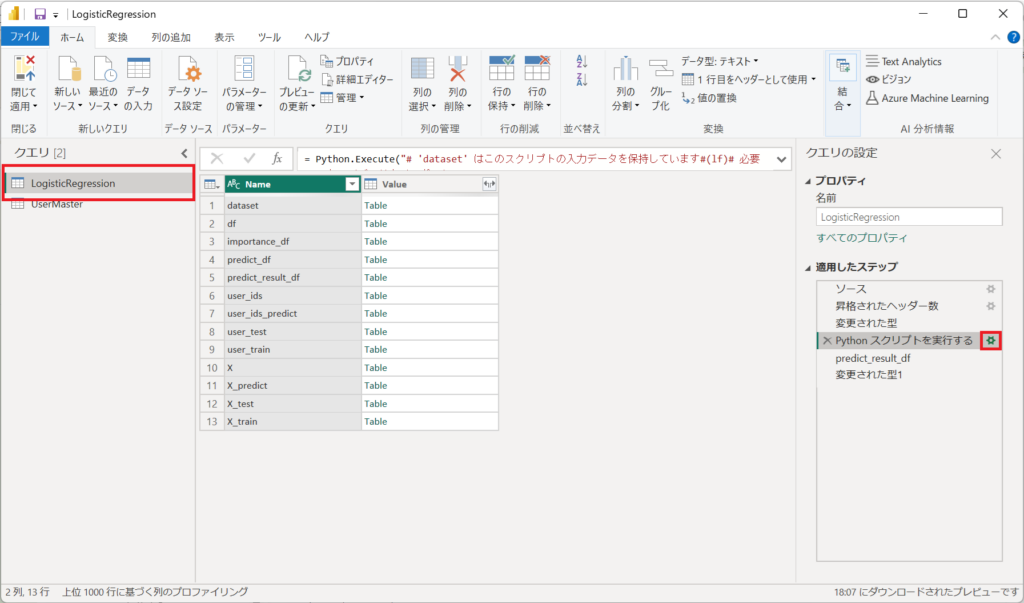
3.スクリプトの枠内へソースコードを貼り付ける。※すべて置き換えてください。
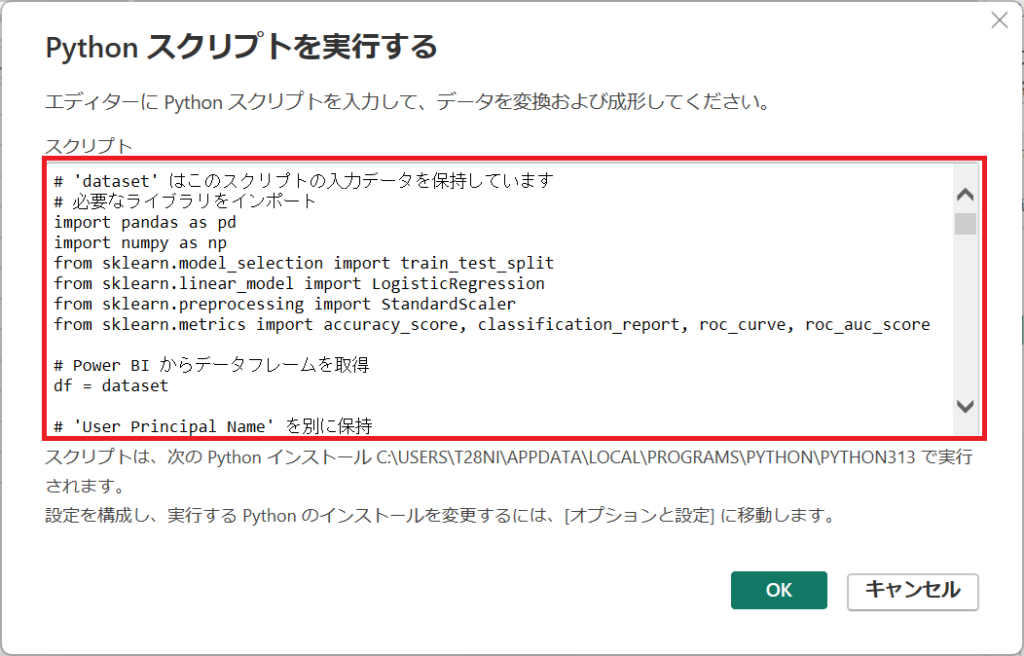
# 'dataset' はこのスクリプトの入力データを保持しています
# 必要なライブラリをインポート
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report, roc_auc_score
import joblib
import os
# ====== 保存済みモデルの読み込み ======
model_path = r'C:\temp\TheGrahp\model\logistic_model.pkl'
scaler_path = r'C:\temp\TheGrahp\model\scaler.pkl'
if os.path.exists(model_path) and os.path.exists(scaler_path):
model = joblib.load(model_path)
scaler = joblib.load(scaler_path)
else:
raise FileNotFoundError("学習済みモデルまたはスケーラーが見つかりません。")
# ====== 固定しきい値の定義 ======
fixed_threshold = 0.5 # 必要に応じて変更可能
# ====== Power BI からのデータを使って予測 ======
df = dataset # Power BI から渡されたデータフレーム
# 'User Principal Name' を保持
user_ids = df[['User Principal Name']]
# 特徴量を抽出
X = df[['WorkingHours', 'BeingWorthDoing', 'WorkEnvironment',
'GrowthCareer', 'HumanRelations', 'EvaluationApproval']]
# スケーリング
X_scaled = scaler.transform(X)
# クラス1の確率を予測
y_prob = model.predict_proba(X_scaled)[:, 1]
# 固定しきい値で予測
y_pred_adjusted = (y_prob > fixed_threshold).astype(int)
# 結果をまとめる
result_df = X.copy()
result_df['User Principal Name'] = user_ids['User Principal Name'].values
result_df['予測値'] = y_pred_adjusted
result_df['クラス1確率'] = y_prob
result_df['使用しきい値'] = fixed_threshold
result_dfコードの解説
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report, roc_auc_score
import joblib
import osデータ処理に必要なライブラリ(pandas, numpy)
joblib: モデルの読み込みに使用
os: ファイル存在チェックに使用
model_path = r'C:\temp\TheGrahp\model\logistic_model.pkl'
scaler_path = r'C:\temp\TheGrahp\model\scaler.pkl'学習済みモデルとスケーラーのファイルパスを定義します。
if os.path.exists(model_path) and os.path.exists(scaler_path):
model = joblib.load(model_path)
scaler = joblib.load(scaler_path)
else:
raise FileNotFoundError("学習済みモデルまたはスケーラーが見つかりません。")ファイルが存在するかを確認し、存在すれば読み込み、なければエラーを出します。
fixed_threshold = 0.5予測結果を分類(0または1)するための基準値(ここでは 0.5)を設定。
しきい値はモデル作成時に「最適なしきい値」を確認して、設定します。
※しきい値は「Power BI × Pythonで学ぶロジスティック回帰分析の解説」へ記載しています。

df = dataset
user_ids = df[['User Principal Name']]dataset はPower BI からスクリプトに渡されるデータフレームです。
ユーザーを識別するためのID列を別途保持しておきます。
X = df[['WorkingHours', 'BeingWorthDoing', 'WorkEnvironment',
'GrowthCareer', 'HumanRelations', 'EvaluationApproval']]
X_scaled = scaler.transform(X)特徴量を抽出し、学習時と同じスケーラーで、データを標準化(平均0・分散1など)します。
y_prob = model.predict_proba(X_scaled)[:, 1]
y_pred_adjusted = (y_prob > fixed_threshold).astype(int)各サンプルがクラス1である確率を出力。しきい値を使って、確率を0か1に変換(分類)
result_df = X.copy()
result_df['User Principal Name'] = user_ids['User Principal Name'].values
result_df['予測値'] = y_pred_adjusted
result_df['クラス1確率'] = y_prob
result_df['使用しきい値'] = fixed_threshold
result_df元の特徴量に加えて、ユーザーID、予測結果(0/1)、確率、しきい値を追加したデータフレームを作成、出力する。
4.「result_df」の「table」を展開する。
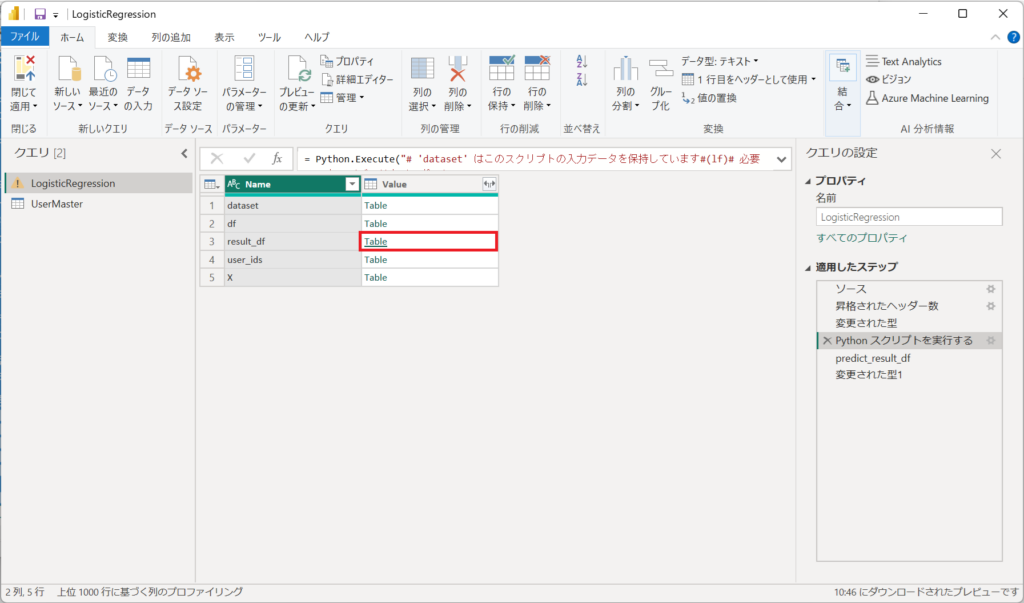
5.「続行」ボタンを押下する。

6.「閉じて適用」ボタンを押下する。
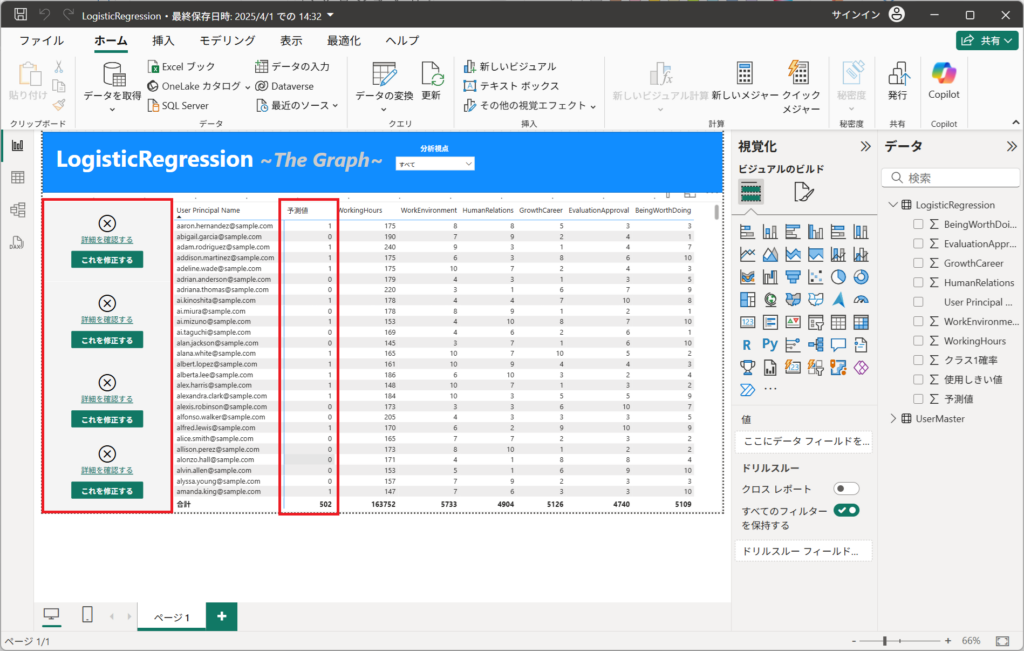
7.画面左のインジケーター(モデルの精度)は、モデル保存時の精度と変わらないため、コードに含めていません。そのため削除していただいて構いません。
テーブルの「予測値」列は、モデルを再利用して(0 or 1)を算出しています。
まとめ
今回は、Pythonで作成した機械学習モデルをPower BIから再利用する方法について、実践的なコード例とともにご紹介しました。今後、AIや機械学習を業務に取り入れていくうえで、「一度作って終わり」ではなく、「活用して成果を出す」ことが求められます。本記事の内容が、皆さんのデータ分析・業務改革の一助になれば幸いです。