はじめに
「Power BI × Pythonで学ぶロジスティック回帰分析の実践」記事で使用したPower BIファイル(.pbix)を利用します。事前に、「Power BI × Pythonで学ぶロジスティック回帰分析の実践」および「Power BI × Pythonで学ぶロジスティック回帰分析の解説」をご一読いただけますと幸いです。
機械学習モデルを保存するとは
「モデルを保存する」と聞くと少し構えてしまうかもしれませんが、実はとってもシンプルな作業です。たとえば、ロジスティック回帰のモデルを作って「この顧客は次月も契約を継続しそうか?」を予測できるようにしたとします。せっかく良いモデルができても、毎回トレーニングから始めていたら手間がかかりますし、再現性の観点からも問題があります。
そこで、学習済みモデルをファイルとして保存しておき、Power BIなど外部ツールでも使い回せるようにすることで、業務効率がグンと上がります。ロジスティック回帰分析や重回帰分析の記事にて機械学習のモデル構築をPythonにて行いましたが、毎回トレーニングから始めていました。
本記事で紹介する「機械学習モデルの保存」は、Power BIの処理性能や再現性の向上という観点からも、非常に有効な手順です。
なぜ機械学習のモデル保存が必要なのか?
なぜわざわざ「モデルの保存」が重要なのでしょうか?理由は主に以下の3つです。
1.毎回の再学習は非効率
ビジネスの現場では、同じ予測タスクを日々繰り返すことが多いです。たとえば、営業リードの成約確率の予測や、需要予測など、こういった場合、モデルを毎回再構築していては時間も計算コストもムダにかかります。
2.再現性の確保
あるモデルで素晴らしい精度が出たとしても、その結果を他のチームメンバーが再現できなければ意味がありません。モデルを保存しておけば、同じアルゴリズム・パラメータ・データ処理の状態を再現できます。
3.Power BIの処理負荷を軽減する
保存したモデルを活用することで、再学習が不要となり、Power BIの負荷が減ります。データ量が多くなるほどトレーニング時間が伸びる可能性は高まります。モデルの保存を1度しておくことで負荷軽減につながります。
方法(アプローチ・使用技術)
今回はPythonの中でも手軽で便利な joblib というライブラリを使用します。
以下がコードです。
import joblib
import os
output_dir = r'C:\temp\TheGrahp\model'
os.makedirs(output_dir, exist_ok=True)
model_path = os.path.join(output_dir, 'logistic_model.pkl')
scaler_path = os.path.join(output_dir, 'scaler.pkl')
joblib.dump(model, model_path)
joblib.dump(scaler, scaler_path)コードの解説
import joblib
import osjoblib: Pythonのオブジェクト(特に大きなNumPy配列や機械学習モデルなど)を効率的に保存・読み込みするためのライブラリ。
os: ファイルやディレクトリのパス操作などを行う標準ライブラリ。
output_dir = r'C:\temp\TheGrahp\model'
os.makedirs(output_dir, exist_ok=True)output_dir は保存先のディレクトリのパスです。
r'...' はraw文字列で、\がエスケープされずそのまま解釈されます(Windowsパス指定に便利)。
os.makedirs(..., exist_ok=True) は、フォルダが存在しない場合は作成します。すでにある場合は何もしません。
model_path = os.path.join(output_dir, 'logistic_model.pkl')
scaler_path = os.path.join(output_dir, 'scaler.pkl')os.path.join() は、パスとファイル名を結合して完全なファイルパスを作成します。
model_path はロジスティック回帰などのモデルを保存するファイル名。
※任意のファイル名を設定することができます。
scaler_path は前処理で使うスケーラー(例えば StandardScaler)を保存するファイル名。
joblib.dump(model, model_path)
joblib.dump(scaler, scaler_path)joblib.dump() で model と scaler をそれぞれファイルに保存します。
これによって、後でモデルやスケーラーを再利用する際に、訓練し直すことなく読み込めるようになります。
コードの設定
上記のコードを「Power BI × Pythonで学ぶロジスティック回帰分析の実践」のコードに追加します。
※コードの体裁見直しは、適宜実施ください。

# 'dataset' はこのスクリプトの入力データを保持しています
# 必要なライブラリをインポート
import pandas as pd
===略===
predict_result_df['適合率_1'] = report['1']['precision']
predict_result_df['再現率_1'] = report['1']['recall']
predict_result_df['F1スコア_1'] = report['1']['f1-score']
# 予測結果の出力
predict_result_df
import joblib
import os
output_dir = r'C:\temp\TheGrahp\model'
os.makedirs(output_dir, exist_ok=True)
model_path = os.path.join(output_dir, 'logistic_model.pkl')
scaler_path = os.path.join(output_dir, 'scaler.pkl')
joblib.dump(model, model_path)
joblib.dump(scaler, scaler_path)
以下のようにファイルが生成されます。
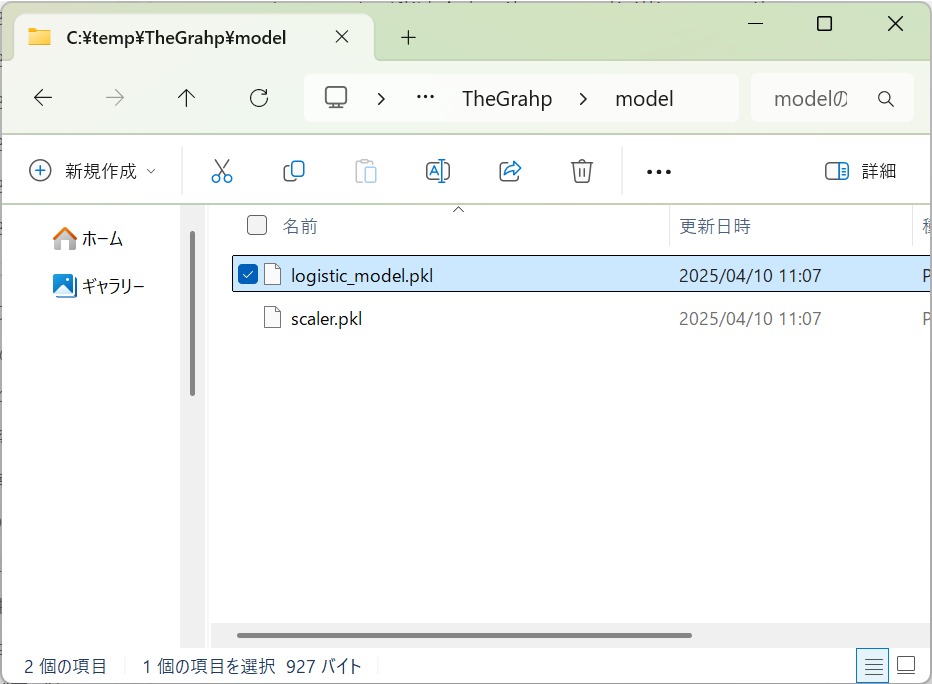

次回は生成されたファイルを用いて、モデルの再利用を行っていきます。
まとめ
今回は、PythonとPower BIを組み合わせて、機械学習モデルを保存する方法について解説しました。モデルを保存するというプロセスは、単なる形式的な手順ではなく、業務にインパクトを与える重要なステップです。
ぜひ、みなさまのビジネス現場でも「モデルの保存」にトライしてみてください!